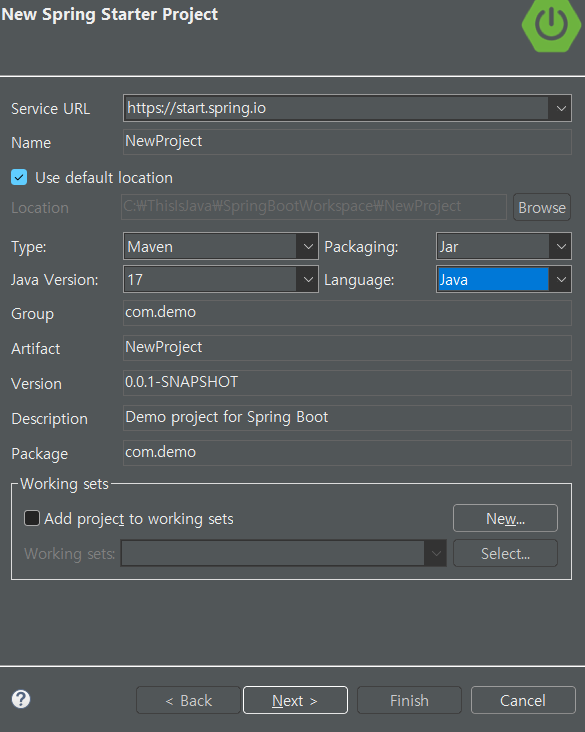
Spring Boot와 JPA를 이용한 REST API 개발사용 기술 : Spring Tool Suite4(STS 4), Spring Boot, Spring Web, Spring Data JPA, Spring Boot DevTools, Oracle DB, Oracle Driver, Lombok, ThymeleafREST API(Representational State Transfer API) : 클라이언트와 서버 간 통신을 HTTP 프로토콜을 기반으로 설계하는 방식Resource(자원) 중심 설계 : URI를 통해 자원 식별HTTP 메서드GET : 데이터 조회POST : 데이터 생성PUT : 데이터 수정DELETE : 데이터 삭제JSON, XML 응답JPA(Java Presistence API) : Ja..