인덱스(Index)
는 데이터베이스에서 데이터를 빠르게 검색하고, 접근할 수 있도록 돕는 검색 구조!
특정 데이터를 빠르게 찾을 수 있도록 돕는 데이터 구조로 데이터베이스에서 인덱스를 사용하면 검색 성능이 향상된다.
데이터베이스에서 인덱스를 생성하면, 데이터를 순차적으로 스캔하지 않고 인덱스 테이블을 사용해 빠르게 원하는 데이터를 찾을 수 있다.
- 구조
- 키(Key) : 데이터를 식별하는 값.
- 값(Value) : 키와 관련된 실제 데이터의 위치 정보
- 종류
- B-Tree 인덱스(기본 인덱스)
- 구조 : 균형 이진 트리구조를 기반으로 데이터를 정렬하여 저장한다.
- 특징 : 범위 검색에 매우 효율적이고, 대부분 데이터베이스에서 기본 인덱스로 사용한다.
[EX- WHERE x BETWEEN : x - 1 AND : x + 1 같은 범위 검색] - 장점 : 빠른 검색, 삽입, 삭제
- 단점 : 정렬된 데이터를 기반으로 하기 때문에 INSERT, DELETE와 같은 연산에서 성능 저하가 있음.
- Hash 인덱스
- 구조 : 해시 함수를 사용해 데이터를 인덱싱. 특정 키를 해시값으로 변환해서 해당 값을 기반으로 데이터에 빠르게 접근한다.
- 특징 : 정확히 일치하는 검색에 매우 빠르다. [EX- WHERE x = 10 같은 조건에서 매우 효율적]
- 장점 : 일치 검색에 빠름.
- 단점 : 범위 검색에는 비효율적이고, 범위 연산이 필요한 쿼리에는 사용할 수 없음.
- Bitmap 인덱스
- 구조 : 비트맵(Bitmap)을 사용해서 데이터를 인덱싱. 각 데이터 값에 대해 비트열을 사용해 인덱스를 생성한다.
- 특징 : 카디널리티가 낮은 컬럼에 유용함. (성별, 지역 등의 값이 적은 컬럼에 적합)
- 장점 : 특정 값에 대해 빠르게 검색할 수 있음.
- 단점 : 데이터가 많을 경우 비트맵 크기가 커져서 성능이 떨어질 수 있음.
- Full-Text 인덱스
- 구조 : 텍스트 데이터를 기반으로 인덱스를 생성. 주로 검색 엔진에 사용된다.
- 특징 : 텍스트나 문서 내에서 단어나 구절을 검색하는데 최적화. [LIKE '%keyword%'와 같은 텍스트 검색에서 유용함]
- 장점 : 텍스트 데이터 검색에 뛰어난 성능.
- 단점 : 대용량의 텍스트 데이터에서 성능 저하.
- Spatial 인덱스
- 구조 : 2D 또는 3D 공간에서 데이터를 인덱싱. 주로 지리 정보 시스템(GIS)에서 사용된다.
- 특징 : 공간 데이터를 저장하고 검색하는데 효율적. (특정 반경 내의 좌표 검색에 사용)
- 장점 : 공간 데이터 검색에서 성능을 크게 향상시킬 수 있음.
- 단점 : 일반적인 데이터와 다르게 공간적 데이터를 관리하는 방식이어서 다른 종류의 데이터와 비교해 처리 방식이 다름.
- B-Tree 인덱스(기본 인덱스)
- 인덱스의 장점
- 검색 성능 향상 : 데이터베이스에서 특정 데이터를 빠르게 찾을 수 있도록 도와준다.(검색 속도 향상, 대용량 데이터에서 효율적인 검색이 가능)
- 정렬 성능 향상 : [ORDER BY]같은 정렬 작업도 빨리 처리할 수 있다.(인덱스가 데이터를 정렬된 상태로 유지하기 때문에 추가적인 정렬 작업 없이 빠르게 결과를 얻을 수 있음)
- 유니크한 값 보장 : 유니크 인덱스(Unique Index)는 데이터베이스에서 중복값을 방지하는데 유용하다.(사용자 ID나 이메일 주소같은 고유 값을 관리할 때 유니크 인덱스를 사용)
- 효율적인 집합 연산 : [JOIN, GROUP BY, DISTINCT]같은 집합 연산에서 성능이 향상된다.(데이터가 정렬되어 있어서 중복값을 쉽게 처리할 수 있음)
- 인덱스의 단점
- 저장 공간 사용 : 인덱스는 별도의 데이터 구조를 추가로 저장해야 하기 때문에 저장 공간을 더 많이 차지한다.
- 쓰기 성능 저하 : [INSERT, UPDATE, DELETE]같은 작업에서 성능 저하를 일으킬 수 있다.(데이터 변경이 있을 때마다 인덱스도 함께 갱신되기 때문에)
- 관리의 복잡성 : 인덱스가 많아지면 관리가 복잡해진다.(적절한 인덱스를 선택하지 않으면, 오히려 성능이 저하될 수 있음)
- 인덱스를 사용하는 이유
- 인덱스를 사용하면 데이터를 순차적으로 스캔하지 않고 인덱스를 통해 빠르게 찾을 수 있어 검색 성능이 향상됨.
- 대용량 데이터에서 인덱스를 사용하지 않으면 검색에 매우 오랜 시간이 걸림.
- 쿼리 실행 시간을 대폭 단축시킬 수 있음.
- 인덱스 최적화
- 적절한 인덱스 선택 : 모든 컬럼에 인덱스를 생성하는 것 보다 자주 검색하는 컬럼에 대해서만 인덱스를 생성해야 한다.
- 인덱스 통계 분석 : 쿼리 실행 계획을 분석하고, 불필요한 인덱스를 제거하거나 쿼리 성능을 최적화하는 방식으로 관리해야 한다.
- 인덱스의 적절한 갱신 : 데이터 변경에 따라 갱신되어야 한다.
INDEX 활용 예제
1. 보물 찾기 게임
- 인덱스를 사용해서 데이터 검색 속도를 비교하는 실험
- 보물을 랜덤한 위치에 배치하고, 유저가 보물을 찾는 속도를 측정하면서 인덱스의 효과를 실험
1-1 프로젝트 생성
Spring Tool Suit 4(STS) 실행 및 Spring Starter Project 생성

1-2 Oracle 데이터베이스 연결 설정
# Application 이름 설정
spring.application.name=Index_1
# Application 유형 설정
spring.main.web-application-type=servlet
# 서버 포트 설정
server.port = 9010
# 데이터 소스 설정(Oracle DB 연결 정보)
# Oracle JDBC 드라이버 클래스
spring.datasource.dbcp2.driver-class-name=oracle.jdbc.OracleDriver
# Oracle DB 접속 URL
spring.datasource.url=jdbc:oracle:thin:@localhost:1521:XE
# Oracle DB 사용자명
spring.datasource.username=test
# Oracle DB 비밀번호
spring.datasource.password=test
# JPA 설정
# 데이터베이스 스키마 자동 업데이트 (기본적으로 테이블 추가/수정)
spring.jpa.hibernate.ddl-auto=update
# DDL 생성 여부 설정
spring.jpa.generate-ddl=true
# SQL 쿼리 출력 여부 (true로 설정 시 쿼리 로그 출력)
spring.jpa.show-sql=true
# Oracle DB에 맞는 Hibernate Dialect 설정
spring.jpa.database-platform=org.hibernate.dialect.OracleDialect
# 출력되는 SQL 쿼리 포맷팅
spring.jpa.properties.jibernate.format-sql=true

1-2 엔티티 클래스 생성
package com.demo.model;
import org.hibernate.annotations.DynamicInsert;
import org.hibernate.annotations.DynamicUpdate;
import jakarta.persistence.Entity;
import jakarta.persistence.Id;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import lombok.ToString;
@Entity
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@Builder
@ToString
@DynamicInsert
@DynamicUpdate
public class Treasure {
@Id
private Long id; // 보물 ID
private String name; // 보물 이름
private double xCoord; // 보물 x좌표
private double yCoord; // 보물 y좌표
}- @Getter : 모든 필드에 대한 Getter 메서드 자동 생성
- @Setter : 모든 필드에 대한 Setter 메서드 자동 생성
- @NoArgsConstructor : 기본 생성자 자동 생성
- @AllArgsConstructor : 모든 필드를 매개변수로 받는 생성자 자동 생성
- @Builder : 빌더 패턴을 사용하여 객체를 생성할 수 있게 해줌
- @ToString : toString() 메서드를 자동으로 생성
- @DynamicInsert : null 값이 아닌 필드만 INSERT 쿼리에서 처리
- @DynamicUpdate : 변경된 필드만 UPDATE 쿼리에서 처리
1-3 Repository 인터페이스 생성
package com.demo.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import com.demo.model.Treasure;
public interface TreasureRepository extends JpaRepository<Treasure, Long> {
}JpaRepository를 상속받아서 기본적인 CRUD 기능을 제공
1-4 Service 계층 생성
package com.demo.service;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.demo.model.Treasure;
import com.demo.repository.TreasureRepository;
@Service
public class TreasureService {
@Autowired
private TreasureRepository treasureRepo;
// 인덱스 없이 성능 측정
public long measureTimeWithoutIndex() {
long startTime = System.currentTimeMillis();
List<Treasure> treasures = treasureRepo.findAll(); // 인덱스 없을 때
long endTime = System.currentTimeMillis();
return endTime - startTime;
}
// 인덱스를 사용한 성능 측정
public long measureTimeWithIndex() {
long startTime = System.currentTimeMillis();
List<Treasure> treasures = treasureRepo.findAll(); // 인덱스 있을 때
long endTime = System.currentTimeMillis();
return endTime - startTime;
}
}
1-5 Controller 계층 생성
package com.demo.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.demo.service.TreasureService;
@RestController
@RequestMapping("/treasures")
public class TreasureController {
@Autowired
private TreasureService treasureService;
// 성능 비교 데이터 반환 (인덱스 적용 전후)
@GetMapping("/performance")
public PerformanceData getPerformanceData() {
long timeWithoutIndex = treasureService.measureTimeWithoutIndex();
long timeWithIndex = treasureService.measureTimeWithIndex();
return new PerformanceData(timeWithoutIndex, timeWithIndex);
}
// 성능 데이터 클래스
public static class PerformanceData {
private long timeWithoutIndex;
private long timeWithIndex;
public PerformanceData(long timeWithoutIndex, long timeWithIndex) {
this.timeWithoutIndex = timeWithoutIndex;
this.timeWithIndex = timeWithIndex;
}
public long getTimeWithoutIndex() {
return timeWithoutIndex;
}
public long getTimeWithIndex() {
return timeWithIndex;
}
}
}
1-6 HTML 생성
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Index 성능 비교</title>
<script src="https://cdn.jsdelivr.net/npm/chart.js"></script>
</head>
<body>
<h1>인덱스 성능 비교</h1>
<canvas id="performanceChart" width="400" height="200"></canvas>
<script>
// 성능 데이터 요청
fetch('/treasures/performance')
.then(response => response.json())
.then(data => {
// 차트 데이터 준비
const performanceData = {
labels: ['인덱스 없음', '인덱스 있음'],
datasets: [{
label: '검색 시간 (ms)',
data: [data.timeWithoutIndex, data.timeWithIndex],
backgroundColor: ['#FF0000', '#00FF00'],
borderColor: ['#FF0000', '#00FF00'],
borderWidth: 1
}]
};
// 차트 옵션 설정
const config = {
type: 'bar',
data: performanceData,
options: {
responsive: true,
plugins: {
legend: {
position: 'top',
},
tooltip: {
callbacks: {
label: function(tooltipItem) {
return tooltipItem.raw + ' ms';
}
}
}
},
scales: {
y: {
beginAtZero: true
}
}
}
};
// 차트 그리기
const ctx = document.getElementById('performanceChart').getContext('2d');
new Chart(ctx, config);
})
.catch(error => console.error('Error fetching performance data:', error));
</script>
</body>
</html>
1-7 랜더 데이터 삽입
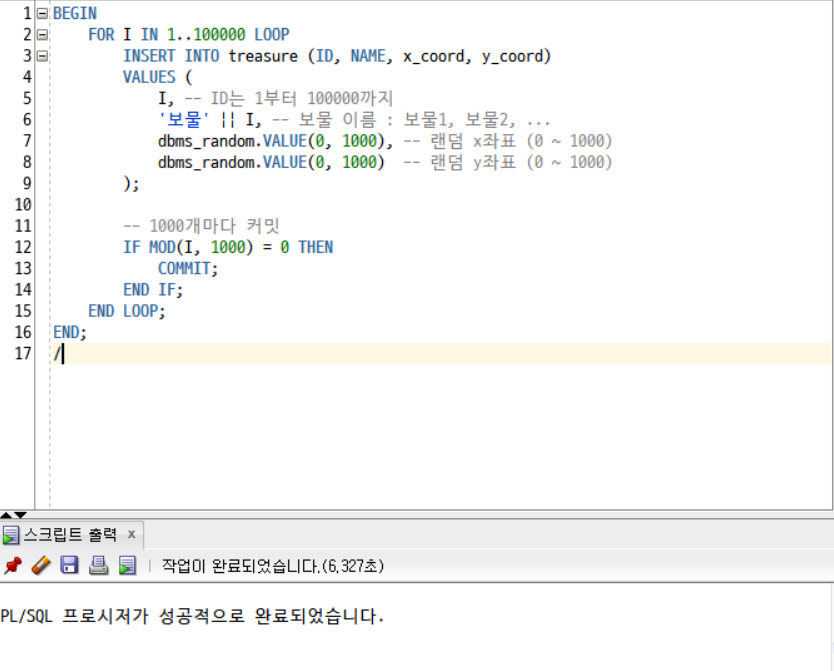
- FOR I IN 1 .. 100000 LOOP : 1부터 100000까지 반복하는 FOR 루프
- INSERT INTO treasure (ID, NAME, x_coord, y_coord) : 데이터 삽입 SQL 문
- ID: 각 반복에서 I값을 사용해 1부터 100,000까지의 ID 값을 삽입
- NAME: NAME 컬럼에는 보물 + 반복된 I 값을 삽입
- x_coord 및 y_coord: x_coord와 y_coord 값은 DBMS_RANDOM.VALUE(0, 1000)을 사용하여 0에서 1000까지의 랜덤 실수 값을 생성
- IF MOD(I, 1000) = 0 THEN COMMIT; END IF : 배치 삽입 최적화 코드
- MOD(I, 1000)는 I를 1000으로 나눈 나머지를 구하는 함수
- BEGIN과 END로 둘러싸인 PL/SQL 블록을 실행하려면 ; 대신 /를 사용해서 명령어를 종료
데이터 삽입 확인

성능 비교
spring boot 실행 후 localhost:9010/ 입력



- 인덱스 없음 = 1292ms
- 데이터베이스가 전체 테이블을 스캔해야 해야함 > 모든 행을 하나씩 확인
- 데이터가 많아질수록 매우 비효율적임
- 전체 테이블을 검색하는 풀 테이블 스캔 방식 == 시간이 많이 걸림
- 인덱스 있음 = 168ms
- 데이터베이스는 인덱스 구조를 사용해서 빠르게 데이터를 찾음
- 쿼리에서 조건을 만족하는 데이터의 위치를 빠르게 찾을 수 있어 성능이 향상됨
- 데이터가 많을 때 효과가 뚜렷
2. 최고 점수 랭킹 보드
2-1 엔티티 클래스 생성
package com.demo.model;
import jakarta.persistence.Entity;
import jakarta.persistence.Id;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import lombok.ToString;
@Entity
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@ToString
@Builder
public class Score {
@Id
private Long userId; // 유저 ID
private Double score; // 점수
}
1-2 Repository 생성
package com.demo.repository;
import java.util.List;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import com.demo.model.Score;
public interface ScoreRepository extends JpaRepository<Score, Long> {
// 인덱스를 사용해서 점수 Top 10 유저 찾기
@Query("SELECT s FROM Score s ORDER BY s.score DESC LIMIT 10")
List<Score> findTop10WithIndex();
// 인덱스를 사용하지 않고 점수 Top 10 유저 찾기
@Query(value = "SELECT * FROM (SELECT s.* FROM Score s ORDER BY s.score DESC) WHERE ROWNUM <= 10", nativeQuery = true)
List<Score> findTop10WithoutIndex();
}
1-3 Controller 계층 생성
package com.demo.controller;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import com.demo.model.Score;
import com.demo.repository.ScoreRepository;
@RestController
public class ScoreController {
@Autowired
private ScoreRepository scoreRepository;
// 유저 점수 및 실행 시간 비교
@GetMapping("/compare-performance")
public Map<String, Object> comparePerformance(@RequestParam boolean useIndex) {
Map<String, Object> response = new HashMap<>();
// 실행 시간 저장 리스트
List<Long> times = new ArrayList<>();
List<Score> scores = new ArrayList<>();
for (int i = 0; i < 10; i++) { // 10번 실행해서 평균 시간 확인
long startTime = System.currentTimeMillis();
if (useIndex) {
scores = scoreRepository.findTop10WithIndex();
} else {
scores = scoreRepository.findTop10WithoutIndex();
}
long endTime = System.currentTimeMillis();
times.add(endTime - startTime);
}
// 유저 ID + 점수 리스트 만들기
List<Map<String, Object>> userScores = new ArrayList<>();
for (Score score : scores) {
Map<String, Object> userScore = new HashMap<>();
userScore.put("userId", score.getUserId());
userScore.put("score", score.getScore());
userScores.add(userScore);
}
response.put("executionTimes", times); // 실행 시간 리스트
response.put("userScores", userScores); // 유저 ID + 점수 리스트
System.out.println("전송 데이터: " + response); // 로그 출력
return response;
}
}
1-5 HTML 생성
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>인덱스 성능 비교</title>
<script src="https://cdn.jsdelivr.net/npm/chart.js"></script>
</head>
<body>
<h2>쿼리 성능 테스트</h2>
<button onclick="runQuery(true)">인덱스 사용</button>
<button onclick="runQuery(false)">인덱스 미사용</button>
<h2>상위 10명 점수 그래프</h2>
<canvas id="scoreChart"></canvas>
<h2>쿼리 실행 시간 그래프</h2>
<canvas id="executionTimeChart"></canvas>
<script>
let scoreChart = null;
let executionTimeChart = null;
async function runQuery(useIndex) {
const response = await fetch(`/compare-performance?useIndex=${useIndex}`);
const data = await response.json();
updateCharts(data, useIndex);
}
function updateCharts(data, useIndex) {
console.log("서버 응답 데이터:", data); // 데이터 확인
if (!data.userScores || !Array.isArray(data.userScores) || data.userScores.length === 0) {
console.error("유저 점수 데이터가 없습니다:", data);
alert("유저 점수 데이터를 가져올 수 없습니다.");
return;
}
if (!data.executionTimes || !Array.isArray(data.executionTimes)) {
console.error("실행 시간 데이터가 없습니다:", data);
alert("실행 시간 데이터를 가져올 수 없습니다.");
return;
}
const labels = data.userScores.map(user => `User ${user.userId}`);
const scores = data.userScores.map(user => user.score);
const executionTimes = data.executionTimes;
const color = useIndex ? "blue" : "red";
const indexLabel = useIndex ? "인덱스 사용" : "인덱스 미사용";
// 점수 그래프 업데이트
const ctx1 = document.getElementById("scoreChart").getContext("2d");
if (scoreChart) scoreChart.destroy();
scoreChart = new Chart(ctx1, {
type: "bar",
data: {
labels: labels,
datasets: [{
label: indexLabel,
data: scores,
backgroundColor: color
}]
}
});
// 실행 시간 그래프 업데이트
const executionLabels = executionTimes.map((_, i) => `${i + 1}회차`);
const ctx2 = document.getElementById("executionTimeChart").getContext("2d");
if (executionTimeChart) executionTimeChart.destroy();
executionTimeChart = new Chart(ctx2, {
type: "line",
data: {
labels: executionLabels,
datasets: [{
label: indexLabel,
data: executionTimes,
borderColor: color,
fill: false
}]
}
});
}
</script>
</body>
</html>
데이터 삽입 후 확인

인덱스 미사용 클릭 시
[console 창]
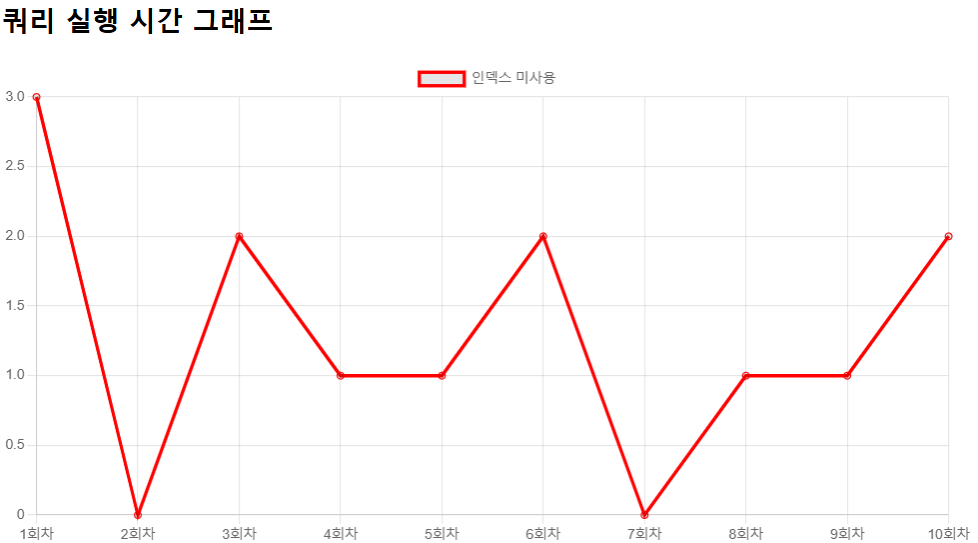
전송 데이터: {executionTimes=[3, 0, 2, 1, 1, 2, 0, 1, 1, 2],
userScores=[{score=983.62, userId=6}, {score=922.92, userId=5}, {score=727.46, userId=10},
{score=510.37, userId=1}, {score=417.94, userId=9}, {score=329.07, userId=4},
{score=328.67, userId=2}, {score=138.89, userId=8}, {score=54.18, userId=7},
{score=15.02, userId=3}]}
인덱스 사용 클릭 시
[console 창]
전송 데이터: {executionTimes=[104, 156, 113, 96, 101, 142, 156, 111, 130, 104],
userScores=[{score=1000.0, userId=175068}, {score=1000.0, userId=979392}, {score=1000.0, userId=903257},
{score=1000.0, userId=384232}, {score=1000.0, userId=311895}, {score=999.99, userId=36485},
{score=999.99, userId=694088}, {score=999.99, userId=656085}, {score=999.99, userId=671158},
{score=999.99, userId=538338}]}

- 인덱스를 사용했을 때
- 인덱스 적용 시 데이터베이스가 빠르게 필요한 순서대로 데이터를 찾을 수 있기 때문에 조회 성능이 향상됨.
- repository의 쿼리문에서 'ORDER BY s.score DESC 를 사용해서 점수 기준으로 내림차순 정렬 데이터를 쉽게 가져올 수 있음.
- 가장 높은 점수를 가진 유저부터 정렬된 데이터를 반환
- 인덱스를 사용하지 않았을 때
- 인덱스가 없으면 데이터베이스는 전체 테이블을 순차적으로 탐색해야 해서 성능이 떨어짐.
- repository의 쿼리문에서'ROWNUM <= 10 ORDER BY s.score DESC'로 상위 10개를 제한했지만, 정렬이 먼저 적용되지 않아서 잘못된 순서로 결과를 반환할 수 있음.
- 인덱스가 없을 때도 정렬을 명확히 적용해야 정확한 순서로 데이터를 가져올 수 있음
'개인 공부' 카테고리의 다른 글
| [Spring Boot] 카카오, 네이버, 구글 SNS 로그인 (0) | 2025.05.17 |
|---|---|
| 데이터베이스?? (0) | 2025.01.19 |
| 객체지향 프로그래밍 OOP (0) | 2025.01.15 |
| JWT를 사용한 Spring Security 기반 인증 시스템 구현 (1) | 2024.12.27 |
| Spring Security를 활용한 사용자 권한 기반 접근 제어 (0) | 2024.12.24 |