데이터 준비
https://www.kaggle.com/datasets/bmofinnjake/naverwebtoon-datakorean?resource=download
Webtoon Dataset in Korean
comics serialized in webtoon platforms (Naver)
www.kaggle.com
위 사이트에서 naver.csv 파일을 받아서 사용했습니다.(로그인 필요)

데이터 로드 및 데이터 확인
import pandas as pd
# CSV 파일 로드
df = pd.read_csv('naver.csv')
# 데이터 크기 확인 : 행과 열 개수
print('데이터 크기 :',df.shape)
print('======================================================================================')
# 컬럼 확인 : 어떤 데이터가 있는지
print('컬럼명 :', df.columns)
print('======================================================================================')
# 상위 5개 행 출력
print(df.head())
print('======================================================================================')
# 데이터 유형 및 결측치 확인 : 숫자형(int, float), 문자형(object), 날짜형(datetime)등
print(df.info())
print('======================================================================================')
# 결측치 확인 : 빈 값 확인
print(df.isnull().sum())
print('======================================================================================')
# 데이터 통계 요약
print(df.describe())



age 컬럼에 102개의 결측치 확인
# age 컬럼에 어떤 값들이 있는지 확인
print(df['age'].value_counts())
결측치를 '---' 값으로 채우기
df['age'] = df['age'].fillna('---')NaN 값이 '---'으로 대체되고 age 컬럼의 데이터 타입이 문자열(object)로 유지
적용 후 데이터 다시 확인
# 결측치가 0이 되어야 함
print(df['age'].isnull().sum())
# '---'값이 추가됬는지 확인
print(df['age'].value_counts())
결측치는 0, '---'값으로 결측치 102개가 변경됨
다른 방법으로 결측치 처리
# 가장 많은 값(최빈값)으로 채우기
most_frequent_age = df["age"].mode()[0]
df["age"] = df["age"].fillna(most_frequent_age)

중복 데이터 제거

불필요한 컬럼 삭제
# 설명(description)과 웹툰 링크(link) 삭제
df = df.drop(columns = ['description', 'link'])
# 삭제 후 상위 5개 행 확인
print(df.head())
데이터 정렬
# 평점이 높은 순으로 데이터 정렬
df = df.sort_values(by = 'rating', ascending = False)
# 상위 10개 데이터 출력 (제목, 작가, 평점, 장르)
print(df[['title', 'author', 'rating', 'genre']].head(10))
print('======================================================================================')
# 데이터 타입 최종 확인
print(df.info())
print('======================================================================================')
# 데이터 정리 후 확인
print(df.head())
print('======================================================================================')

평점 분포 시각화
- 웹툰 평점이 어떻게 분포되어 있는지 확인 및 이상치(극단적으로 높거나 낮은 평점) 파악
# 히스토그램(Histogram) : 연속형 데이터(숫자형 데이터)의 분포를 보여주는 그래프
# 데이터를 여러 개의 구간으로 나누고, 각 구간에 속하는 데이터를 막대 그래프로 보여줌
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib
# 그래프 스타일
plt.style.use('seaborn-v0_8-darkgrid')
# 한글 폰트 설정
matplotlib.rc('font', family='Malgun Gothic') # windows
# matplotlib.rc('font', family='AppleGothic') # Mac
# 히스토그램 그리기
plt.figure(figsize = (10, 5))
sns.histplot(df['rating'], bins = 30, kde = True, color = 'green')
plt.title('웹툰 평점 분포', fontsize = 14)
plt.xlabel('평점', fontsize = 12)
plt.ylabel('웹툰 수', fontsize = 12)
plt.show()
- 막대가 높은 곳 → 해당 구간에 데이터가 많음 (웹툰 평점이 이 구간에 많이 분포됨)
- 막대가 낮은 곳 → 해당 구간에 데이터가 적음
- kde=True 옵션 → 데이터 분포를 부드럽게 보여주는 커브 추가
# 박스플롯(Boxplot) : 데이터의 분포와 이상치를 시각적으로 확인하는데 유용한 그래프
# 구조 : 아래쪽 경계(Q1)-1사분위수(데이터 하위 25%), 가운데 선(Q2)-중앙값(50%),
# 위쪽 경계(Q3)-3사분위수(상위 75%)
# 이상치 : 박스 밖의 점들-일반적인 데이터 범위를 벗어난 값
matplotlib.rc('font', family='Malgun Gothic') # windows
plt.figure(figsize = (8,4))
sns.boxplot(x = df['rating'], color = 'blue')
plt.title("웹툰 평점 분포 (Boxplot)", fontsize=14)
plt.xlabel("평점", fontsize=12)
plt.show()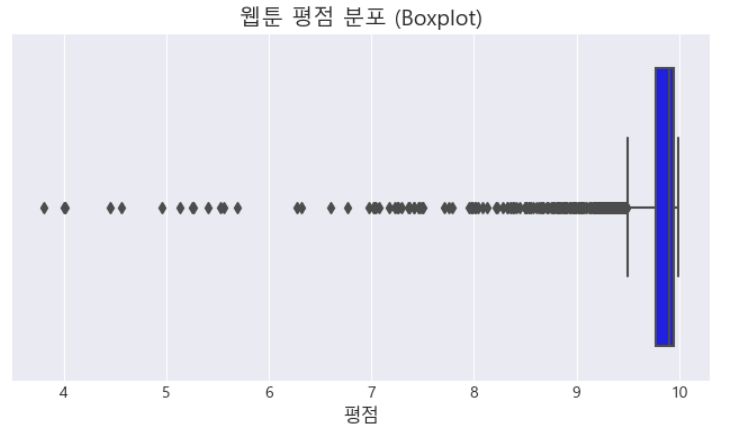
- 박스가 넓을수록 → 데이터의 변동 폭(분산)이 큼
- 박스가 좁을수록 → 데이터가 특정 값 근처에 몰려 있음
- 이상치(Outlier) 가 많으면 → 데이터에 극단적인 값이 많음
추천 시스템 구현
1. 장르 기반 추천
# 장르(genre)컬럼에 어떤 값들이 있는지 확인
print(df['genre'].value_counts())
import random
def genre_based_recommendation(df, genre, top_n=10, random_n=10):
# 해당 장르 웹툰 필터링
genre_filtered = df[df['genre'].apply(lambda x: genre in x)]
# 평점이 높은 웹툰 10개
top_rated = genre_filtered.sort_values(by = 'rating', ascending = False).head(top_n)
# 랜덤 웹툰 10개
random_webtoons = genre_filtered.sample(n = random_n)
# 평점이 높은 웹툰과 랜덤 웹툰을 합침
recommended_webtoons = pd.concat([top_rated[['title', 'rating', 'genre', 'age']],
random_webtoons[['title', 'rating', 'genre', 'age']]])
return recommended_webtoons
recommendation_webtoons = genre_based_recommendation(df, '개그')
print('추천 웹툰 \n', recommendation_webtoons)
랜덤 추천 웹툰이 계속 같은지 확인

평점이 높은 웹툰 10개는 항상 같은 웹툰 추천
랜덤 웹툰 10개는 '오늘도 형제는 평화롭다' 이후에 계속 다른 웹툰을 추천해줌
2. 평점 기반 추천
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.preprocessing import StandardScaler
import pandas as pd
def rating_based_recommendation(df, top_n=3, base_titles=None):
# 1. 장르 정보를 One-Hot Encoding 방식으로 벡터화
genre_list = ['스토리', '로맨스', '드라마', '판타지', '스릴러', '액션', '개그', '일상', '무협/사극', '스포츠', '감성']
def genre_to_one_hot(df, genre_list):
for genre in genre_list:
df[genre] = df['genre'].apply(lambda x: 1 if genre in x else 0)
return df
# 장르 벡터화
df = genre_to_one_hot(df, genre_list)
# 2. 평점 데이터 스케일링
rating_data = df[['rating']]
scaler = StandardScaler()
rating_data_scaled = scaler.fit_transform(rating_data)
# 3. 장르 벡터와 평점 데이터를 합침
genre_data = df[genre_list] # 장르 관련 컬럼
feature_data = genre_data.join(pd.DataFrame(rating_data_scaled, columns=['rating']))
# 4. 코사인 유사도 계산
similarity_matrix = cosine_similarity(feature_data)
# 5. 웹툰 간 유사도를 데이터프레임으로 변환
similarity_df = pd.DataFrame(similarity_matrix, index=df['title'], columns=df['title'])
# 6. 각 웹툰에 대해 가장 유사한 상위 N개의 웹툰을 추천
recommendations = {}
for title in base_titles:
if title not in df['title'].values:
print(f"웹툰 '{title}'은(는) 데이터에 존재하지 않습니다.")
continue
similar_webtoons = similarity_df[title].sort_values(ascending=False)[1:top_n+1]
recommendations[title] = [(webtoon, df[df['title'] == webtoon]['rating'].values[0])
for webtoon in similar_webtoons.index]
return recommendations
# 예시 웹툰 목록 (기준 웹툰 5개)
base_titles = ['마루는 강쥐', '수능일기', '오늘의 순정망화', '프린스의 왕자', '킬러 김빵빵']
# 추천 결과 출력
recommendations = rating_based_recommendation(df, top_n=3, base_titles = base_titles)
# 결과 출력
for title, recommended_webtoons in recommendations.items():
print(f"기준 웹툰: {title}")
recommended_list = ", ".join([f"{webtoon}({rating:.2f})" for webtoon, rating in recommended_webtoons])
print(f"평가 기반 추천: {recommended_list}\n")
print()
웹툰 추천을 5개로 했을 때
(top_n = 5)로 수정

웹툰 데이터 관리를 위한 CRUD 기능
Create : 생성
Read : 읽기
Update : 업데이트
Delete : 삭제

위에서 머신러닝 모델에 적용하기 위해 각 장르를 개별 컬럼으로 변환했기 때문에
웹툰의 genre(장르) 컬럼이 벡터화 되어있음

웹툰 추가
# 1. 웹툰 추가 함수 만들기
import pandas as pd
from datetime import datetime
def add_webtoon(df, title, rating, genre, file_path = "naver.csv"):
# df의 마지막 id 찾기
new_id = df['id'].max() + 1 if not df.empty else 1 # 데이터가 없을 경우 id = 1부터 시작
# 현재 시간 가져와서 문자열로 변환
current_time = datetime.now().strftime("%Y - %m - %d %H : %M : %S")
# 새로운 웹툰 데이터 생성
new_webtoon = pd.DataFrame([{
"id" : new_id,
"title" : title,
"rating" : rating,
"genre" : genre,
"age" : "전체연령가",
"author" : "(이름없음)",
"date" : current_time,
"completed" : "(알수없음)",
"free" : "(알수없음)"
}])
# 새로운 데이터가 기존 데이터프레임의 열과 동일한 타입을 갖도록 설정
new_webtoon = new_webtoon.astype({
'id' : 'int',
'title' : 'str',
'rating' : 'float',
'genre' : 'str',
'age' : 'str',
'author' : 'str',
'date' : 'str',
'completed' : 'str',
'free' : 'str'
})
# 기존 df와 새로운 웹툰 데이터의 열을 동일하게 맞추기 (타입 일치)
# 기존 df의 열과 new_webtoon의 열이 일치하도록 보장
new_webtoon = new_webtoon[df.columns]
# 새로운 데이터가 기존 데이터프레임의 열과 동일한 타입을 갖도록 설정
new_webtoon = new_webtoon.astype(df.dtypes.to_dict())
# 기존 df와 새로운 웹툰 데이터 결합
df = pd.concat([df, new_webtoon], ignore_index = True)
# 업데이트된 df를 naver.csv 파일에 저장
df.to_csv(file_path, index = False, encoding = 'utf-8')
return df # 수정된 df를 반환
# 웹툰 추가 테스트
df = pd.DataFrame(columns=["id", "title", "author", "genre", "rating", "date", "completed", "age", "free"]) # 빈 DataFrame 생성
df = add_webtoon(df, '새로운 웹툰1', 7.8, '공포')
df = add_webtoon(df, '새로운 웹툰2', 7.8, '공포')
df = add_webtoon(df, '새로운 웹툰3', 7.8, '공포')
# 추가된 것을 확인하고 출력
added_webtoon = df[df['genre'] == '공포']
# 추가된 웹툰 출력
print(added_webtoon)
웹툰 삭제
# 2. 웹툰 삭제 함수 만들기
def delete_webtoon(df, webtoon_id = None, webtoon_title = None, file_path = 'naver.csv'):
# 웹툰 삭제 조건이 id 또는 title일 경우
if webtoon_id:
df = df[df['id'] != webtoon_id] # id를 기준으로 삭제
elif webtoon_title:
df = df[df['title'] != webtoon_title] # 제목을 기준으로 삭제
else:
print('삭제할 웹툰의 id 또는 title을 제대로 입력해주세요.')
return df
df.to_csv(file_path, index = False, encoding = 'utf-8')
return df# 웹툰 삭제 테스트
df = delete_webtoon(df, webtoon_id = 2) # id가 2인 웹툰 삭제
df = delete_webtoon(df, webtoon_title = '새로운 웹툰3') # 제목이 새로운 웹툰3인 웹툰 삭제
new_webtoon = df[df['genre'] == '공포']
print(new_webtoon)
새로운 웹툰2, 3이 삭제된 것을 확인
웹툰 업데이트
# 3. 업데이트 함수 만들기
def update_webtoon(df, webtoon_title, new_data, file_path = 'naver.csv'):
# title이 일치하는 웹툰 찾기
if webtoon_title in df['title'].values:
# 새로운 날짜 생성 (현재 시간)
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
# 날짜를 new_data에 추가 (입력한 값에 날짜가 없으면 자동으로 추가)
new_data['date'] = current_time
# 해당 웹툰의 데이터만 업데이트
for col, new_value in new_data.items():
if col in df.columns:
df.loc[df['title'] == webtoon_title, col] = new_value
df.to_csv(file_path, index=False, encoding='utf-8')
print(f"웹툰 '{webtoon_title}'이(가) 성공적으로 업데이트되었습니다.")
else:
print(f"웹툰 '{webtoon_title}'을(를) 찾을 수 없습니다.")
return df# 업데이트 테스트
# author를 홍길동, completed를 False, free를 True로 업데이트
new_data = {
'author' : '홍길동',
'rating' : 6.74,
'completed' : False,
'free' : True
}
df = update_webtoon(df,'새로운 웹툰1', new_data)
webtoon = df[df['genre'] == '공포']
print(webtoon)
이번 프로젝트에서는 웹툰 데이터셋을 활용하여 데이터 전처리부터 추천 시스템 구현까지 다양한 작업을 실험해보았습니다. 데이터를 로드하고 전처리하는 과정에서 결측치 처리, 중복 제거, 불필요한 컬럼 삭제 등의 기본적인 데이터 클린징 기법을 익혔습니다. 또한, 평점 분포 시각화와 장르 기반 및 평점 기반 추천 시스템을 구현하면서 데이터를 분석하고 추천 시스템의 원리를 적용하는 경험을 했습니다. 웹툰 CRUD 기능을 추가하여 데이터 수정, 삭제, 추가 작업을 실시간으로 처리하는 방법을 배우며 실용적인 데이터를 다루는 능력을 키웠습니다.
'Python' 카테고리의 다른 글
| [Python] 신경망 모델 훈련 (0) | 2025.03.14 |
|---|---|
| [Python] 비지도 학습 (1) | 2025.03.13 |
| [Python] 트리 앙상블 (0) | 2025.03.11 |
| [Python] 머신러닝 (3) (0) | 2025.03.10 |
| [Python] 머신러닝 (2) (0) | 2025.03.08 |